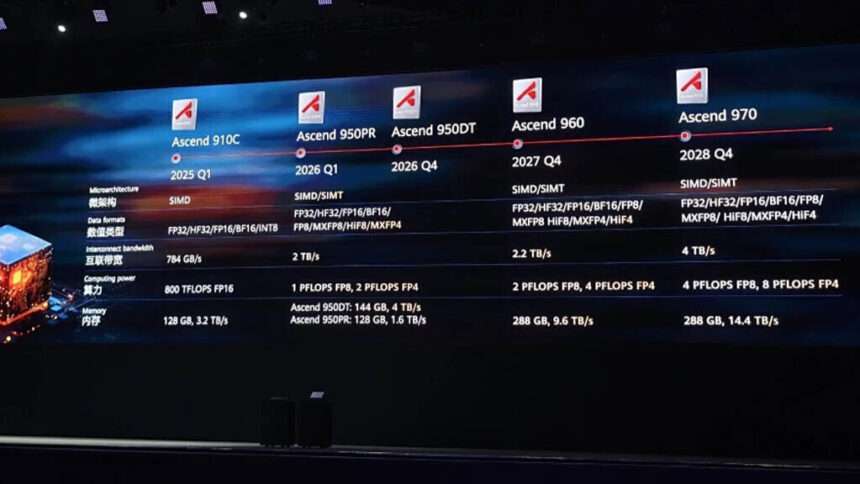
Huawei aprovechó su evento Connect 2025 para presentar una ambiciosa hoja de ruta de hardware que combina la primera memoria HBM de desarrollo propio de la compañía con una nueva generación de aceleradores Ascend AI, y el mensaje fue claro: Huawei competirá en escala en lugar de supremacía de un solo chip. Si bien aún está por detrás de NVIDIA en el rendimiento por chip, las soluciones a escala de sistema pueden ser competitivas. La compañía confirmó la familia Ascend 950 para principios de 2026 en dos variantes. Un modelo, etiquetado como 950PR, se describe con aproximadamente 128 GB de HBM interno y aproximadamente 1.6 TB / s de ancho de banda, mientras que el 950DT aumenta la memoria a 144 GB y empuja el ancho de banda hacia 4 TB / s. Huawei también esbozó planes a más largo plazo para los dispositivos Ascend 960 y Ascend 970 que llegarán en 2027 y 2028, prometiendo mayores capacidades de memoria agregada, mayor ancho de banda de interconexión y un soporte más amplio para formatos de precisión FP8.
Huawei enmarcó su estrategia competitiva en torno a un empaquetado denso y una red agresiva, no en un rendimiento bruto por chip. La compañía mostró SuperPoD y describió SuperClusters construidos a partir de esos bloques de construcción, impulsados por un nuevo protocolo de interconexión Lingqu y enlaces ópticos que tienen como objetivo unir cientos de miles de tarjetas. Huawei dijo que un supernodo Atlas 950 del cuarto trimestre de 2025 basado en unidades Ascend 950 apuntará a cargas de trabajo FP8 a exaescala, y que los futuros clústeres Atlas 960 aumentarán aún más el número de chips y el rendimiento. Su SuperCluster más grande entregará la asombrosa cantidad de 524 ExaFLOPS de cómputo FP8 y un ZettaFLOP completo de cómputo FP4. Esto es posible gracias a 64 Atlas SuperPoD, que albergan hasta 524.288 aceleradores en total. Un solo sistema como este puede admitir múltiples laboratorios de IA y sus ejecuciones de entrenamiento e inferencia. El clúster occidental más grande en desarrollo hoy en día es Colossus 2 de xAI, que utilizará más de 550,000 GPU NVIDIA GB200 y GB300. La escala de los diseños de Huawei ahora es comparable a lo mejor que NVIDIA y sus socios pueden lograr.
El enfoque de Huawei se basa en una filosofía simple: si la memoria y las redes pueden ser propiedad y los sistemas pueden escalar mucho más allá de un solo rack, entonces el rendimiento agregado puede compensar las brechas a nivel de matriz que tienen con los fabricantes de chips occidentales como NVIDIA, AMD y otros. Si esos SuperClusters se materializan como se prometió, podrían obligar a los operadores de centros de datos a repensar las compensaciones entre la eficiencia de un solo chip y el rendimiento masivo a nivel de clúster. Aún así, para implementaciones nacionales, la red eléctrica de China puede soportar mucha más carga y permitirse desperdiciar algo de energía adicional para producir más rendimiento informático de IA. Los centros de datos y los clústeres de IA con sede en EE. UU. a menudo tienen energía limitada, lo que impide la creación de sistemas masivos, con pocas excepciones. China, por otro lado, puede permitírselo, y este gráfico de SemiAnalysis pinta la imagen de las diferencias de generación de energía entre dos países.









