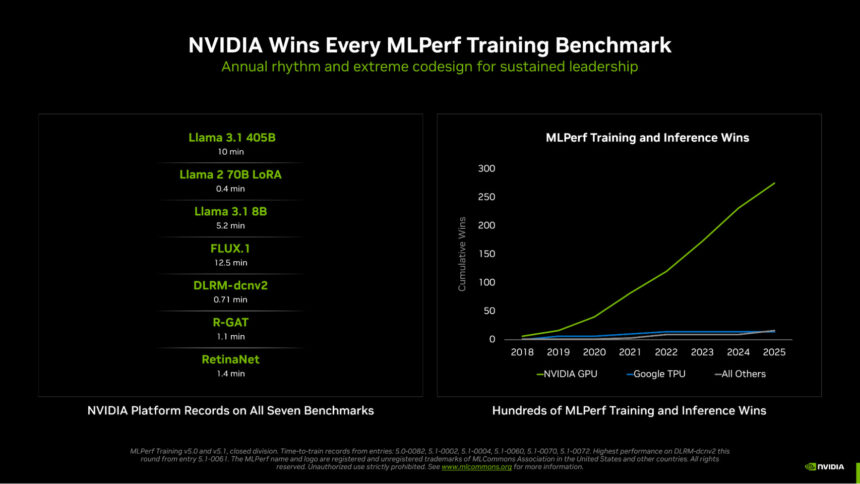
En la era del razonamiento de IA, entrenar modelos más inteligentes y capaces es fundamental para escalar la inteligencia. Ofrecer el rendimiento masivo para cumplir con esta nueva era requiere avances en GPU, CPU, NIC, redes de escalabilidad vertical y horizontal, arquitecturas de sistemas y montañas de software y algoritmos. En MLPerf Training v5.1, la última ronda de una serie de pruebas estándar de la industria sobre el rendimiento del entrenamiento de IA, NVIDIA arrasó en las siete pruebas, brindando el tiempo más rápido para entrenar en grandes modelos de lenguaje (LLM), generación de imágenes, sistemas de recomendación, visión por computadora y redes neuronales gráficas.
NVIDIA también fue la única plataforma que envió resultados en cada prueba, lo que subraya la rica capacidad de programación de las GPU NVIDIA y la madurez y versatilidad de su pila de software CUDA.
NVIDIA Blackwell Ultra redobla sus esfuerzos
El sistema a escala de rack GB300 NVL72, impulsado por la arquitectura de GPU NVIDIA Blackwell Ultra, hizo su debut en MLPerf Training en esta ronda, luego de una demostración récord en la ronda de MLPerf Inference más reciente.
En comparación con la arquitectura Hopper de la generación anterior, el GB300 NVL72 basado en Blackwell Ultra entregó más de 4 veces el preentrenamiento de Llama 3.1 405B y casi 5 veces el rendimiento de ajuste fino de Llama 2 70B LoRA utilizando la misma cantidad de GPU.
Estas ganancias fueron impulsadas por las mejoras arquitectónicas de Blackwell Ultra, incluidos los nuevos Tensor Cores que ofrecen 15 petaflops de computación de IA NVFP4, el doble de computación de capa de atención y 279 GB de memoria HBM3e, así como nuevos métodos de entrenamiento que aprovecharon el enorme rendimiento de computación NVFP4 de la arquitectura.
Al conectar varios sistemas GB300 NVL72, la plataforma NVIDIA Quantum-X800 InfiniBand, la primera plataforma de red escalable de 800 Gb/s de extremo a extremo de la industria, también hizo su debut en MLPerf, duplicando el ancho de banda de red escalable en comparación con la generación anterior.
Rendimiento desbloqueado: NVFP4 acelera el entrenamiento de LLM
La clave de los resultados sobresalientes de esta ronda fue realizar cálculos utilizando la precisión NVFP4, una primicia en la historia de MLPerf Training.
Una forma de aumentar el rendimiento informático es construir una arquitectura capaz de realizar cálculos en datos representados con menos bits y luego realizar esos cálculos a un ritmo más rápido. Sin embargo, una precisión más baja significa que hay menos información disponible en cada cálculo. Esto significa que el uso de cálculos de baja precisión en el proceso de entrenamiento requiere decisiones de diseño cuidadosas para mantener la precisión de los resultados.
Los equipos de NVIDIA innovaron en cada capa de la pila para adoptar la precisión FP4 para el entrenamiento de LLM. La GPU NVIDIA Blackwell puede realizar cálculos FP4, incluido el formato NVFP4 diseñado por NVIDIA, así como otras variantes FP4, al doble de la velocidad de FP8. Blackwell Ultra aumenta eso a 3 veces, lo que permite que las GPU ofrezcan un rendimiento informático de IA sustancialmente mayor.
NVIDIA es la única plataforma hasta la fecha que ha presentado resultados de MLPerf Training con cálculos realizados utilizando la precisión FP4 mientras cumple con los estrictos requisitos de precisión del punto de referencia.
NVIDIA Blackwell escala a nuevas alturas
NVIDIA estableció un nuevo récord de tiempo de entrenamiento Llama 3.1 405B de solo 10 minutos, impulsado por más de 5,000 GPU Blackwell que trabajan juntas de manera eficiente. Esta entrada fue 2,7 veces más rápida que el mejor resultado basado en Blackwell presentado en la ronda anterior, como resultado de un escalado eficiente a más del doble del número de GPU, así como del uso de la precisión NVFP4 para aumentar drásticamente el rendimiento efectivo de cada GPU Blackwell.
Para ilustrar el aumento de rendimiento por GPU, NVIDIA presentó los resultados de esta ronda utilizando 2.560 GPU Blackwell, logrando un tiempo de entrenamiento de 18,79 minutos, un 45% más rápido que la última ronda de presentación con 2.496 GPU.
Nuevos puntos de referencia, nuevos récords
NVIDIA también estableció récords de rendimiento en los dos nuevos puntos de referencia agregados esta ronda: Llama 3.1 8B y FLUX.1.
Llama 3.1 8B, un LLM compacto pero altamente capaz, reemplazó al modelo BERT-large de larga duración, agregando un LLM moderno y más pequeño al conjunto de referencia. NVIDIA envió resultados con hasta 512 GPU Blackwell Ultra, estableciendo el listón en 5,2 minutos para entrenar.
Además, FLUX.1, un modelo de generación de imágenes de última generación, reemplazó a Stable Diffusion v2, y solo la plataforma NVIDIA envió los resultados en el punto de referencia. NVIDIA envió los resultados utilizando 1.152 GPU Blackwell, estableciendo un tiempo récord de entrenamiento de 12,5 minutos.
NVIDIA continuó manteniendo registros sobre la red neuronal de gráficos existente, la detección de objetos y las pruebas del sistema de recomendación.
Un ecosistema de socios amplio y profundo
El ecosistema NVIDIA participó ampliamente en esta ronda, con presentaciones convincentes de 15 organizaciones, incluidas ASUSTeK, Dell Technologies, Giga Computing, Hewlett Packard Enterprise, Krai, Lambda, Lenovo, Nebius, Quanta Cloud Technology, Supermicro, University of Florida, Verda (anteriormente DataCrunch) y Wiwynn.
NVIDIA está innovando a un ritmo de un año, impulsando aumentos significativos y rápidos del rendimiento en el preentrenamiento, el post entrenamiento y la inferencia, allanando el camino hacia nuevos niveles de inteligencia y acelerando la adopción de IA.